
Ground Plane Polling for 6DoF Pose Estimation of Objects on the Road
Published in IEEE Transactions on Intelligent Vehicles, 2020
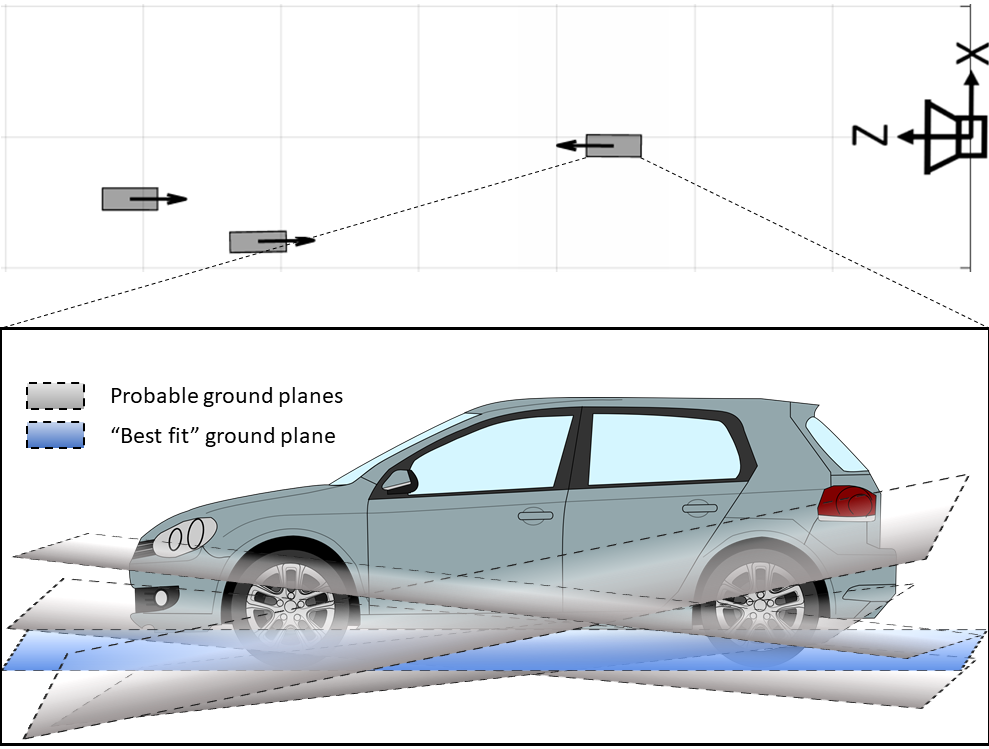
This paper introduces an approach to produce accurate 3D detection boxes for objects on the ground using single monocular images. We do so by merging 2D visual cues, 3D object dimensions, and ground plane constraints to produce boxes that are robust against small errors and incorrect predictions. First, we train a single-stage convolutional neural network (CNN) that produces multiple visual and geometric cues of interest: 2D bounding boxes, 2D keypoints of interest, coarse object orientations and object dimensions. Subsets of these cues are then used to poll probable ground planes from a pre-computed database of ground planes, to identify the “best fit” plane with highest consensus. Once identified, the “best fit” plane provides enough constraints to successfully construct the desired 3D detection box, without directly predicting the 6DoF pose of the object. The entire ground plane polling (GPP) procedure is constructed as a non-parametrized layer of the CNN that outputs the desired “best fit” plane and the corresponding 3D keypoints, which together define the final 3D bounding box. This single-stage, single-pass CNN results in superior localization and orientation estimation compared to more complex and computationally expensive monocular approaches.